






(Bloomberg Opinion) — In the run-up to the U.S. presidential election, I wrote a script that automatically produced a daily news story showing the victory probabilities for the two main candidates according to FiveThirtyEight, the polling aggregation website. Every time the story ran, I would get a few angry emails calling FiveThirtyEight and its election forecast model ugly names and predicting that it would fail as it did in 2016.
I was agnostic about the election’s outcome (and, as a non-American, I didn’t think either of the candidates was worthy of running the world’s most powerful nation). Instead of arguing with the Donald Trump supporters who wrote the emails, I always replied that the forecasts were a historical document. The development of successful multi-factor prediction models is the next step away from the obsolete reliance on public polling that my Bloomberg Opinion colleague Cathy O’Neill persuasively decried right after the election.
Now that the dust has settled a little, I’d say the FiveThirtyEight model, while not perfect, won on points — just as it lost on points in 2016. Four years ago, it correctly predicted that Hillary Clinton would win the popular vote, but it also had Donald Trump losing Florida, Pennsylvania, Michigan and Wisconsin, where he ended up winning narrowly to gain an Electoral College victory. This year, the model got Florida wrong again but correctly predicted swings to the Democrats in Pennsylvania, Michigan and Wisconsin — and gave Joe Biden better odds in Georgia than it gave Trump.
Given how close the vote has been in battleground states, the success or failure of a poll-based prediction model often appears to hang on sheer luck. Pollsters are always fighting last year’s war — this time around, they apparently corrected for voters’ education levels better than in 2016 but failed to predict the higher turnout among enthusiastic Trump supporters. But FiveThirtyEight did fine-tune its methodology for 2020, especially because of the Covid-19 pandemic. And although the model remained mostly poll-based, it took account of other factors, such as the number of Covid cases and deaths. It also put some work into the economic indicators used for the predictions. I can’t say this with certainty, but these improvements possibly contributed to the increase in the model’s predictive power.
Even if the public polling is off, as it often will be in a country as diverse and complex as the U.S., there are always other data to factor in for better accuracy. One can actually do without the current polls and still produce a better prediction than the models that use them. Nate Silver, the founder of FiveThirtyEight, has long argued against the so-called fundamental models, which rely on economic and historical factors to the detriment of polling. Yet at least one academic whom Silver has criticized, Alan I. Abramowitz of Emory University, predicted the 2020 outcome with more precision than FiveThirtyEight did.
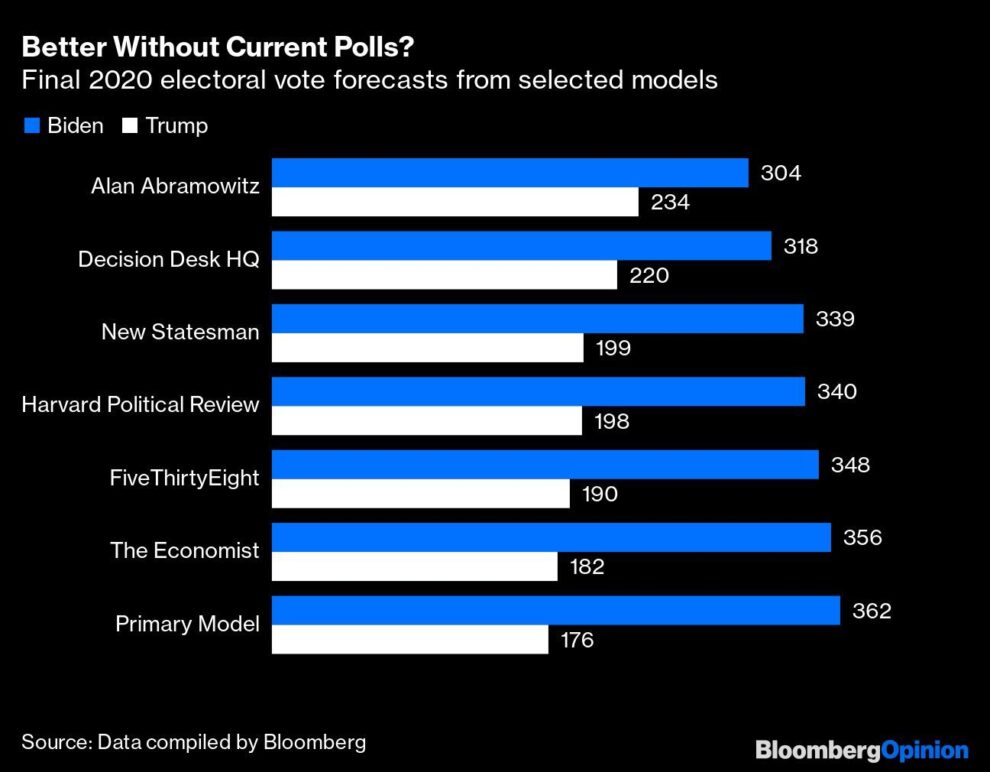
The FiveThirtyEight model gave Biden 348 electoral votes on Nov. 3. Abramowitz, in a paper entitled “It’s the Pandemic, Stupid!,” presented a forecasting model that used only one factor — the president’s approval rating at the end of June of the election year. This was a radical simplification of Abramowitz’s usual “time-for-change” model, which used the approval rating, the real GDP change in the second quarter of the election year and a dummy variable based on whether a first-term incumbent was running.
In 2016, that three-factor model correctly forecast a narrow Trump victory. In 2020, Abramowitz argued that a deliberately induced virus-related recession would make the GDP change irrelevant as a predictor and that the increased political polarization would reduce the incumbent’s built-in advantage (he still only used elections with an incumbent running to build his model). Based on Trump’s June approval rating alone, which was a negative 15%, he predicted a Biden victory by 319 electoral votes to 219; he also wrote that should the rating improve to a negative 5% by late October, Biden would be likely to win 304-234.
Trump’s rating did improve to about negative 7% in the polls taken in the last days of October. If Biden’s narrow victory in Georgia is confirmed, he will win 306-232.
Of all the models I have seen, Abramowitz’s regression came the closest to the actual result. Indeed, using both the “How would you vote if the election were held now” polls and the presidential job approval ratings arguably reduces the accuracy of the model. The Harvard Political Review model, which did just that, forecast 340 electoral votes for Biden.
Polling isn’t an exact science, as Americans have discovered time and again. Building prescient models is an art. It takes both a strong intuition and rigorous analysis to decide which factors to include and how to weight them in line with an unpredictable situation. How, for example, does one interpret the negative 0.47 correlation (according to my calculations) of Biden’s percentage of votes by state with the percentage of the states’ population testing positive for Covid-19 by late October? Were Trump voters more careless, allowing the virus to spread wider, or were the hardest-hit states more tired of lockdown-style measures and thus less disposed to support Biden?
Abramowitz needed both courage and sound judgment to change his model as he did. His example — and, actually, that of FiveThirtyEight this year — shows that adjusting factor weights in a prediction model in response to the changing situation can be a rewarding exercise. In some cases, current public polling should pack a weaker punch as part of a complex forecast, or it can be discounted altogether.
If I were building a model for the next election cycle, I’d look more closely at campaign fundraising and spending data. The latest election was, by all accounts, the most expensive in history, and Biden consistently outraised and outspent Trump by a large margin (as I’ve seen every day from running automated story scripts based on ad spending data). Biden’s campaign also has been helped by much more independent spending than Trump’s, according to Federal Election Commission data. Such huge spending is a new phenomenon, and older studies of its effects on voting are probably irrelevant if contests remain this expensive. I would think the latest election’s unusually high turnout was not unrelated to the massive spending.
The inclusion of data from the Facebook Ad Library that illuminate candidates’ Facebook Ad strategies for different states and demographics could also be useful. That’s a new dataset, available for the first time with the 2020 presidential election; given the growing share of voter attention grabbed by online resources such as Facebook, it might be worth adjusting models accordingly.
Polls may never get much better than they are today — but better predictive models can be developed nonetheless. Then sophisticated election watchers can pick the ones to track based on methodological choices. As for the rest of us, we’ll have to rely on track records. These track records are already being built today — and given that Biden’s victory was predicted by pretty much every model, they are, perhaps, improving in comparison with 2016.
This column does not necessarily reflect the opinion of the editorial board or Bloomberg LP and its owners.
Leonid Bershidsky is a member of the Bloomberg News Automation team based in Berlin. He was previously Bloomberg Opinion’s Europe columnist. His Russian translation of George Orwell’s “1984” is due out in early 2021.
For more articles like this, please visit us at bloomberg.com/opinion
Subscribe now to stay ahead with the most trusted business news source.
©2020 Bloomberg L.P.


